🏗️☕ Engineering the Muse: Day 2 Ops for GenAI Tools
The demo went great. The crowd cheered when the AI wrote a perfect haiku about Kubernetes. You’re buzzing.
But then comes the morning after. Everyone loves a demo. No one loves the morning after.
This is Day 2. The day when the “magic” wears off and the reality of maintenance sets in. You realise that while your prompt worked perfectly yesterday, a slight tweak to the model version, or just the inherent randomness of the universe, might make it hallucinate wildly tomorrow.
In the coffee world, this is the difference between a home enthusiast pulling one god-tier espresso shot on a Sunday morning, and a commercial barista serving 500 consistent lattes during the 8 AM rush. The first is art; the second is engineering.
With Scribe, my Gemini CLI extension for writing, I wanted to prove that we can treat “Prose as Code.” That means we can’t just cross our fingers and hope the AI is in a good mood. We need a testing pipeline.
Here is how we engineer the muse, from local linting to cloud-scale evaluation.
🚫 The Problem with Testing “Vibes”
In traditional software, we have it easy. We write a unit test: assert(add(2, 2) === 4). It’s binary. It passes, or it fails.
But how do you write a unit test for a creative writing bot? assert(write_blog_post() === “???”)
You can’t. Large Language Models are stochastic (a fancy word for “random”). If you ask the same question twice, you might get two different answers. Worse, we often fall into the trap of “Vibe Checking”—running the prompt once, reading it, nodding, and shipping it.
That’s not engineering. That’s guessing.
Some developers swing too far the other way and try to “Over-Engineer” it. They build complex LLM chains just to check if a JSON object is valid. That’s burning expensive tokens for problems we solved in the 90s.
We need a middle ground. We need the GenAI Testing Pyramid. This isn’t the only way, but it’s the method that’s kept my production logs clean and my users happy.
📐 The Testing Pyramid (Reimagined)
For Scribe, I rely on a three-layer approach. The goal is to catch issues as cheaply and quickly as possible, moving from the developer’s laptop to the cloud.
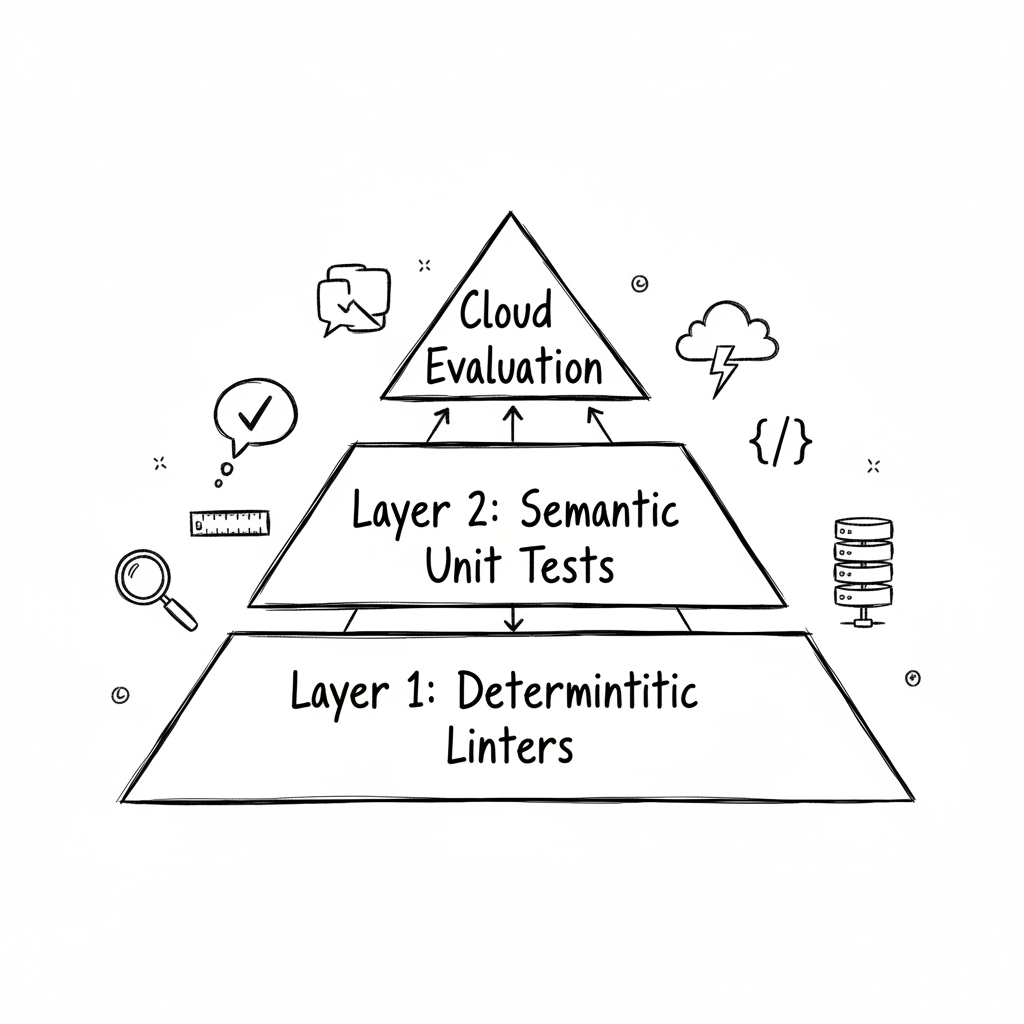
Layer 1: The Foundation (Deterministic Linters)
Tool: ESLint (for code), Vale (for prose). Cost: Free. Speed: Milliseconds.
Don’t use an LLM to check if your markdown is formatted correctly. That’s like hiring a Michelin-star chef to chop onions. It’s a waste.
I use Vale, a prose linter, to enforce basic style rules (like “no future tense” or “sentence casing”). It runs locally and instantly. If Scribe outputs bad Markdown, the CI pipeline fails before we even think about calling an AI model.
Layer 2: The Inner Loop (Semantic Unit Tests)
Tool: promptfoo.
Cost: Low (API calls).
Speed: Seconds.
This is where the fun happens for local development. I use promptfoo to test for intent and tone.
Instead of checking for exact string matches, promptfoo lets me write “Semantic Assertions.” For example, I can test the “Coach” persona (configured in promptfooconfig.yaml):
|
|
This runs locally on my machine. It’s my “unit test” suite. If I tweak the system prompt and suddenly the Coach stops catching hedging language, promptfoo yells at me.
Layer 3: The Outer Loop (Cloud-Scale Evaluation)
Tool: Google Cloud Vertex AI Evaluation (AutoSxS). Cost: Higher. Speed: Minutes.
Local tests are great, but “grading your own homework” has limits. When I’m preparing a major release for Scribe, I need a rigorous, unbiased audit.
This is where Vertex AI comes in. Specifically, a feature called AutoSxS (Automatic Side-by-Side).
☁️ Deep Dive: The “Pro” Tier with Vertex AI
Imagine you have two versions of your prompt: v1 (Current) and v2 (Experimental). You think v2 is funnier, but is it accurate?
AutoSxS effectively creates a “Digital Q-Grader Panel.” It takes a dataset of inputs, generates responses from both versions, and then asks a third, much larger model (the “Arbiter”) to judge them based on specific criteria like Safety, Groundedness, and Instruction Following.
It gives you a win rate. “v2 beat v1 75% of the time.”
This is crucial for enterprise compliance. In Fintech or MedTech, you can’t just say “it looks good.” You need a report saying, “We have mathematically verified that this model hallucinates 40% less than the previous version.”
🚀 Conclusion: Engineering the Muse
Building AI tools is thrilling, but it’s time we grew up a bit.
Reliability isn’t about perfectly controlling the chaos of an LLM; it’s about building a harness around it. It’s about picking the right tool for the job:
- Linters for syntax (don’t burn tokens).
promptfoofor logic (local dev loop).- Vertex AI for scale (production trust).
So, the next time you’re building a “cool demo,” ask yourself: What happens on Day 2?
☕ The Takeaway
Start small. You don’t need Vertex AI today. But please, for the love of coffee, install a linter. If you want to see this pipeline in action, check out the .github/workflows folder in the Scribe repo.
Now, I’m off to brew a proper pot of tea. This engineering malarkey is thirsty work.