
🧠⚙️ Roasting the Beans: Model Development for GenAI
Just like a master roaster coaxes out the unique flavors of each coffee bean, we need to fine-tune our GenAI models for optimal performance. In our last post, we laid the groundwork by “grinding the beans” — building the application framework for our GenAI coffee shop. Now, it’s time to focus on the heart of our GenAI brew: the model itself! This is where ‘roasting the beans’ comes in, and just like coffee beans, GenAI models can be prepared in various ways to achieve different results.
Think of your Large Language Model (LLM) as a raw, green coffee bean. It’s got potential, but it needs to be roasted (developed) to unlock its full flavor and aroma. Model development is the crucial process of tailoring these powerful LLMs to excel at specific tasks, transforming them from general-purpose tools into finely tuned instruments for your unique needs. It’s about taking that raw potential and crafting it into something truly special — a model that’s not just good, but perfect for your application.
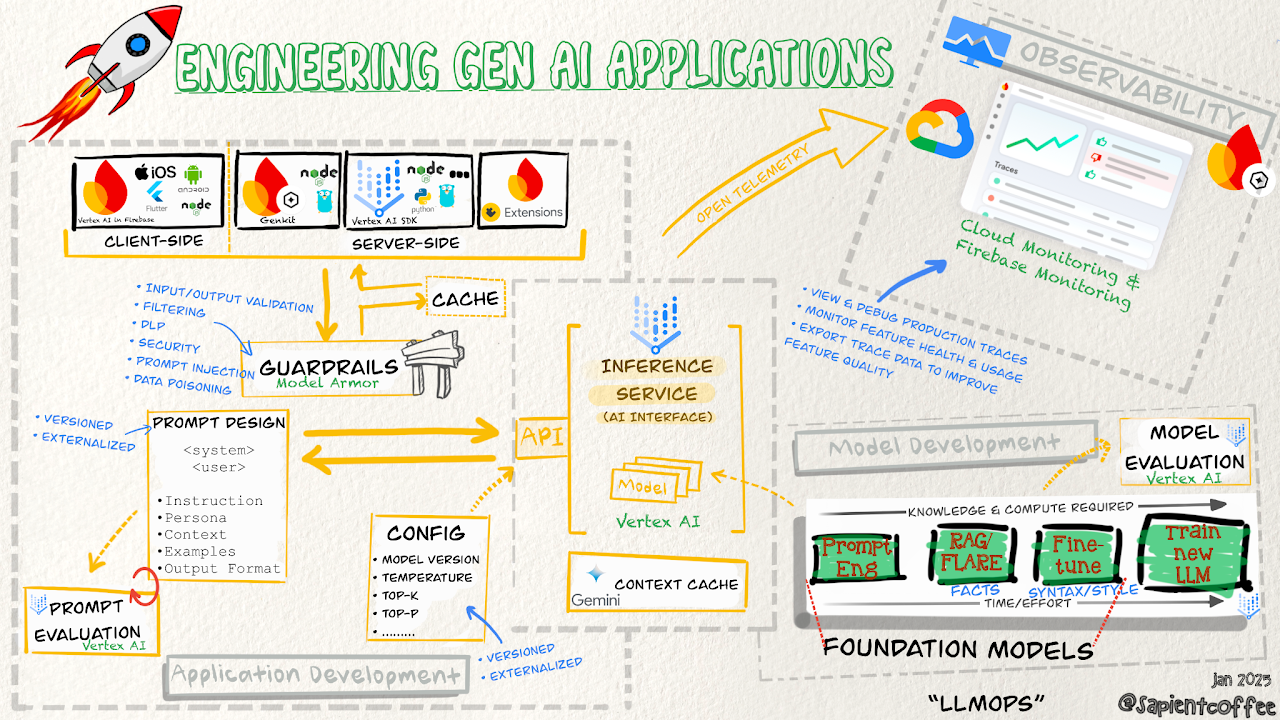
The Model Development Spectrum — From a Quick Warm-up to a Full Roast
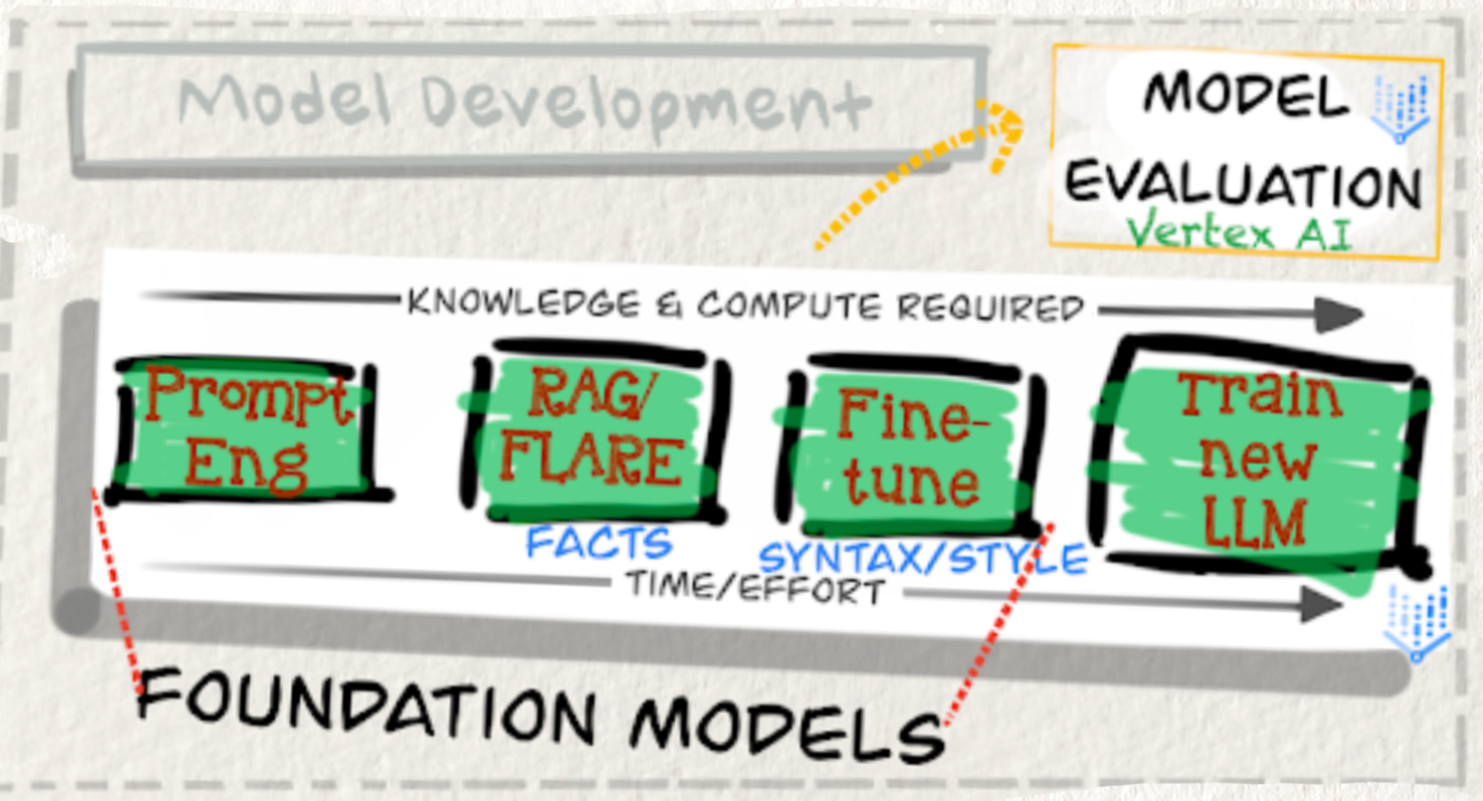
We have a spectrum of model development methods at our disposal, each like a different roasting technique, offering varying levels of control and specialization:
- Prompt Engineering: This is like dialing in your espresso machine for the perfect shot. We meticulously craft prompts, experimenting with parameters to guide the Gemini foundation models (or others) to produce the desired outputs. It’s about finding that sweet spot in your existing setup, making small adjustments to get a better result without fundamentally changing anything. Think of it as tweaking your brewing temperature and grind size — quick, effective, and readily adjustable. Prompt evaluation, often using tools within Vertex AI, helps us iterate and refine our “prompt recipes.”
- Retrieval-Augmented Generation (RAG): Think of RAG as adding a splash of flavored syrup to your coffee. It enriches the model’s knowledge by connecting it to external data sources — the ‘context cache’ we mentioned in the last post! This allows our application to access up-to-date facts and specific information, improving the relevance and accuracy of the generated content. It’s like giving your coffee a richer, more complex profile by adding extra ingredients. Techniques like FLARE can even further enhance the quality of information we retrieve — ensuring we’re using the best “syrup” possible.
- Fine-tuning: Fine-tuning is like adjusting the roast level — a light roast might be perfect for a delicate floral coffee, while a dark roast brings out the smoky notes in a Sumatran bean. Fine-tuning involves taking a pre-trained foundation model and training it further on a specific dataset to optimize it for a particular task or domain. This requires more knowledge and compute resources, often provided by platforms like Vertex AI. It’s a balancing act of time, effort, and the desired level of specialization. You’re essentially teaching the model to develop a taste for a specific kind of “flavor.”
- Building Custom Models: For the ultimate control, you might consider training a new Large Language Model (LLM) from scratch. This is the equivalent of sourcing your own green coffee beans and setting up your own roastery! It’s the most resource-intensive approach but offers maximum customization and potential for cutting-edge innovation. This is for when you want to create a truly unique and signature “blend” from the ground up. Choosing the right model development path depends entirely on your specific needs, budget, and timeline. Each method has its own benefits and trade-offs in terms of effort, complexity, and performance. Let’s zoom in on a couple of these key “roasting” techniques.
Retrieval Augmented Generation (RAG) — Brewing with Better Facts
Retrieval Augmented Generation (RAG) is a truly powerful technique that a developer can enhance the capabilities of LLMs by combining their generative power with the ability to access and retrieve information from external knowledge sources. Imagine your LLM is a brilliant barista, but they only know the recipes they were initially trained on. RAG is like giving that barista access to the entire library of coffee knowledge! By combining the LLM’s generative abilities with external knowledge sources, RAG lets you create applications that are not just creative, but also incredibly well-informed.
Benefits of RAG are like the benefits of using higher quality coffee beans:
- Improved Accuracy: Grounding responses in real-world knowledge. No more serving up factually incorrect coffee brewing methods!
- Enhanced Relevance: Providing contextually relevant information. Making sure the coffee recommendation actually matches the customer’s preferences.
- Increased Informativeness: Incorporating knowledge from diverse sources. Drawing upon the wisdom of coffee experts from around the globe.
- Reduced Hallucinations: Mitigating the generation of incorrect or nonsensical outputs. Less chance of the barista inventing a coffee bean that doesn’t exist!
Both Vertex AI and Genkit provide excellent tools to help you implement RAG in your GenAI applications. And if you’re looking for architectural guidance, there are numerous resources available on Google Cloud to assist you in setting up your RAG “knowledge library.”
Fine-tuning — Specialty Roasts for Specialty Tasks
Fine-tuning is where we move beyond simple adjustments and start to reshape the model itself. Going beyond prompt engineering, fine-tuning involves adjusting the model’s internal parameters. Think of it as going beyond just tweaking the espresso machine and actually modifying the roasting process itself. This allows the model to learn task-specific knowledge and adapt to the nuances of a target domain.
The benefits of Fine-tuning are like the benefits of crafting a specialty roast:
- Enhanced Performance: Improved accuracy and efficiency for specific tasks. A roast optimized for espresso extraction will outperform a general-purpose roast in espresso applications.
- Structured Outputs: Consistent generation of outputs in desired formats (e.g., JSON, YAML). Ensuring every cup of coffee is consistently presented and formatted for the customer.
- Domain Specialization: Adapting models for specialized areas like medical or legal text analysis. Creating a roast specifically designed to pair with certain desserts or dishes in a fine dining context.
- Instruction Following: Improved adherence to specific instructions and output styles. Training the barista to follow precise instructions for complex coffee orders.
- Safety Enhancements: Mitigating the risk of generating harmful or biased content. Roasting in a controlled environment to minimize any unwanted or harmful byproducts.
However, like any specialty roast, there are trade-offs: Fine-tuning requires significantly more computational resources than simple prompt engineering. It’s a more involved process requiring expertise and a deeper understanding of your desired outcome.
Building Custom Models — The Artisan Roastery Approach
For the ultimate level of customization and control, building a custom LLM from scratch is the equivalent of setting up your own artisan roastery. This approach offers maximum flexibility, allowing you to tailor every aspect of the model to your exact specifications. However, it demands significant expertise, resources, and time. It’s a journey for those seeking truly unique and cutting-edge AI solutions.
A Systematic Approach — The Engineering of Flavor
Whether you’re tweaking prompts, implementing RAG, or fine-tuning models, remember that model development, like coffee roasting, is both an art and a science. Just like master roasters meticulously experiment with roasting profiles and bean origins, effective model development requires a systematic approach. Experimentation, iteration, and careful evaluation are key to unlocking the full potential of your GenAI models and creating truly exceptional applications.
Model development is absolutely crucial for unlocking the full potential of LLMs. By carefully considering the available techniques and their trade-offs, developers can choose the best approach for their specific needs. Whether it’s crafting clever prompts, leveraging external knowledge with RAG, fine-tuning existing models, or building custom solutions, the journey of model development empowers us to create more accurate, reliable, and impactful AI applications.
Our coffee is almost ready! In the final post, we’ll talk about observability — the key to ensuring your GenAI app is brewing success 24/7. Don’t forget to refill your cup!