
A deployment strategy is more and more important as you want to get new features and functionality to your users as quickly and seamlessly as possible. Gone is the day that you can get away with throwing up an “Essential maintenance” message, users will start to get annoyed and move elsewhere (might be a bit harder when it comes to Government services so might not be the best example, you get the point though).
The idea of Pivotal Platform (both Cloud Foundry and Kubernetes/K8s) is to make the developers life easier and allow them to be more productive, getting new versions and features into the wild as quick as possible. What does this mean when it comes to routing traffic to applications?
Deploying new versions of applications to your users can be complex however a number of strategies exist. The following are common ones that I tend to come across;
- Replace
- Canary
- Green/Blue
- Rolling Deployment/Incremental
- A/B Testing
So what are these strategies and how can you use them?
Replace
A more traditional approach to deploying new versions, this was the way I used to do deployments 5+ years ago during 72 hour release windows. It would involve some level of downtime while the old version is taken down and the new version brought up. It was easy to implement, either power down or direct the load balancer to a holding page.
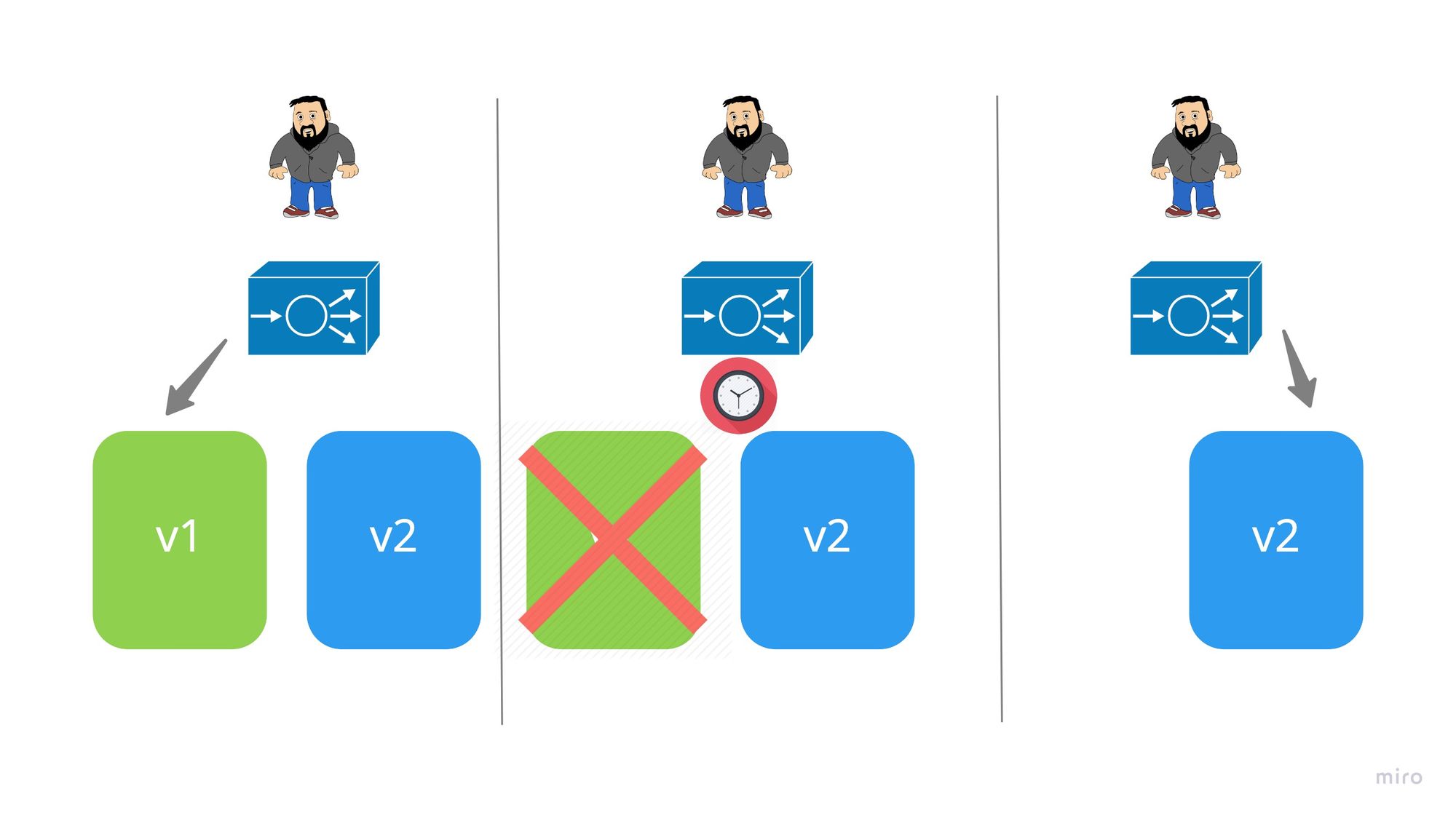
This strategy can be useful why you have limited resources (say reusing bare metal, limited vCPU/Memory on IaaS/PaaS Quotas etc.).
The challenge of this pattern historically is that 6 - 12 months of development had been bundled up into the release (hence the 72 hour release window). These days it is less likely that you would bundle so many changes up for a massive release! This strategy might be beneficial if you need to make backing service changes, say update a schema.
Kubernetes
To achieve this with K8s the following can be added to your manifest.
spec:
strategy:
type: Recreate
Cloud Foundry
Prior to the v3 API in Cloud Foundry cf push would pretty much to this! Should you want to ensure this strategy is followed simply delete the app or unbind the route from the running application.
Canary
Think of how miners used canaries in years gone by, they would be used to give an early warning that something is going wrong (high gas levels). If you are not confident that your new version will function as expected you may want to split a certain amount of traffic to the new version while the majority is still directed to the old version. This means you can closely monitor logs/metrics/performance of the new version looking for early indicators that something is going wrong.
Altering the traffic weight so that all traffic goes to the new version or in case of issue all back to the old version resulting in only a small proportion of the user base being impacted. The rollout can take time while monitoring is done.
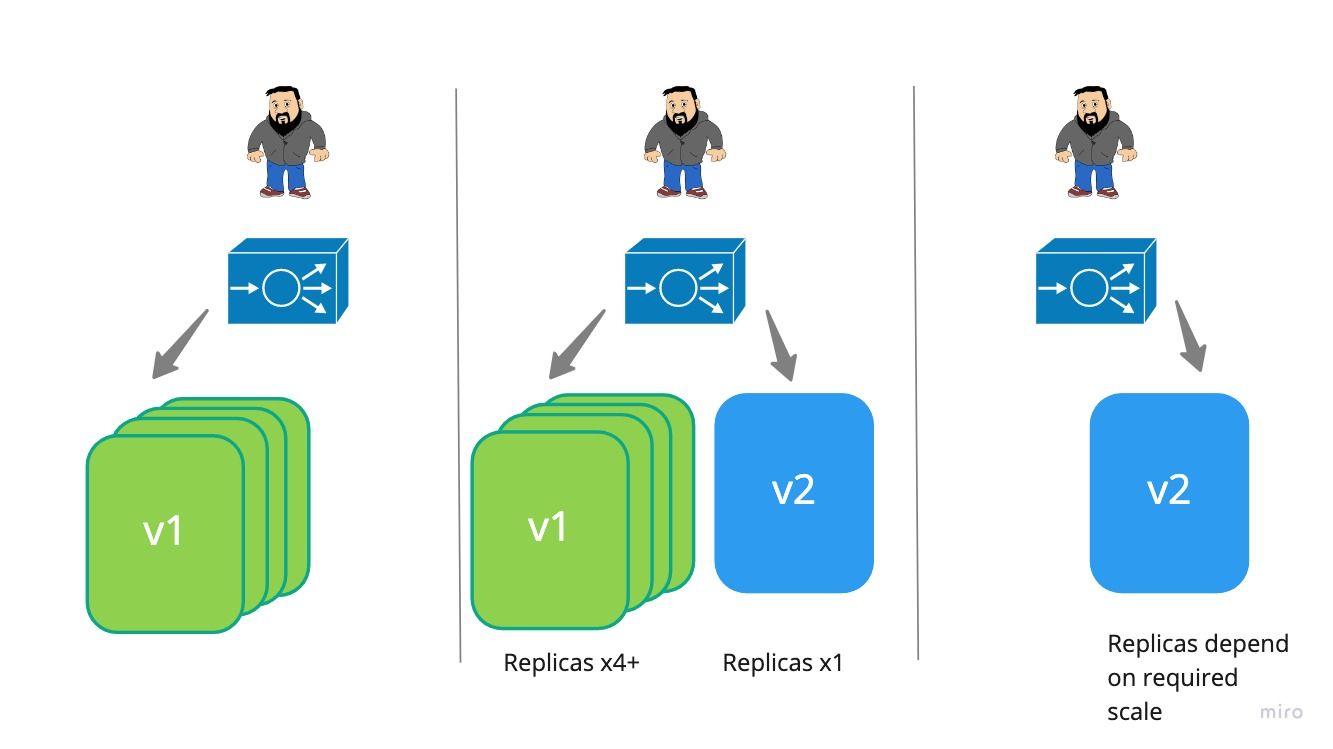
Kubernetes
You can apply the canary deployment technique using the native way by adjusting the number of replicas or if you use Nginx as Ingress controller you can define fine grained traffic splitting via Ingress annotations.
apiVersion: v1
kind: Service
metadata:
name: clijockey-service
spec:
selector:
app: clijockey-app
...
apiVersion: apps/v1
kind: Deployment
metadata:
name: clijockey
replicas: 9
...
labels:
app: clijockey-app
track: stable
...
image: clijockey-app:v3
apiVersion: apps/v1
kind: Deployment
metadata:
name: clijockey-canary
replicas: 1
...
labels:
app: clijockey-app
track: canary
...
image: clijockey-app:v4
Cloud Foundry
You would scale the v1 of your application out with cf scale www -i 5 and then bind the production route to both v1 and v2 as detailed below in the Green/Blue deployment description.
Green/Blue
This strategy is probably one of the most widely used, it has one version (say green) deployed along side a second version (say blue), however all user traffic is directed to one version. Once the second version, blue, has been evaluated, tested and you are happy it’s time to take production workloads the traffic gets switched reducing downtime.
It also means that you can run the new version for a period of time with the old version ready to take over should issues get detected. Although if the application has state you may need to make extra considerations.
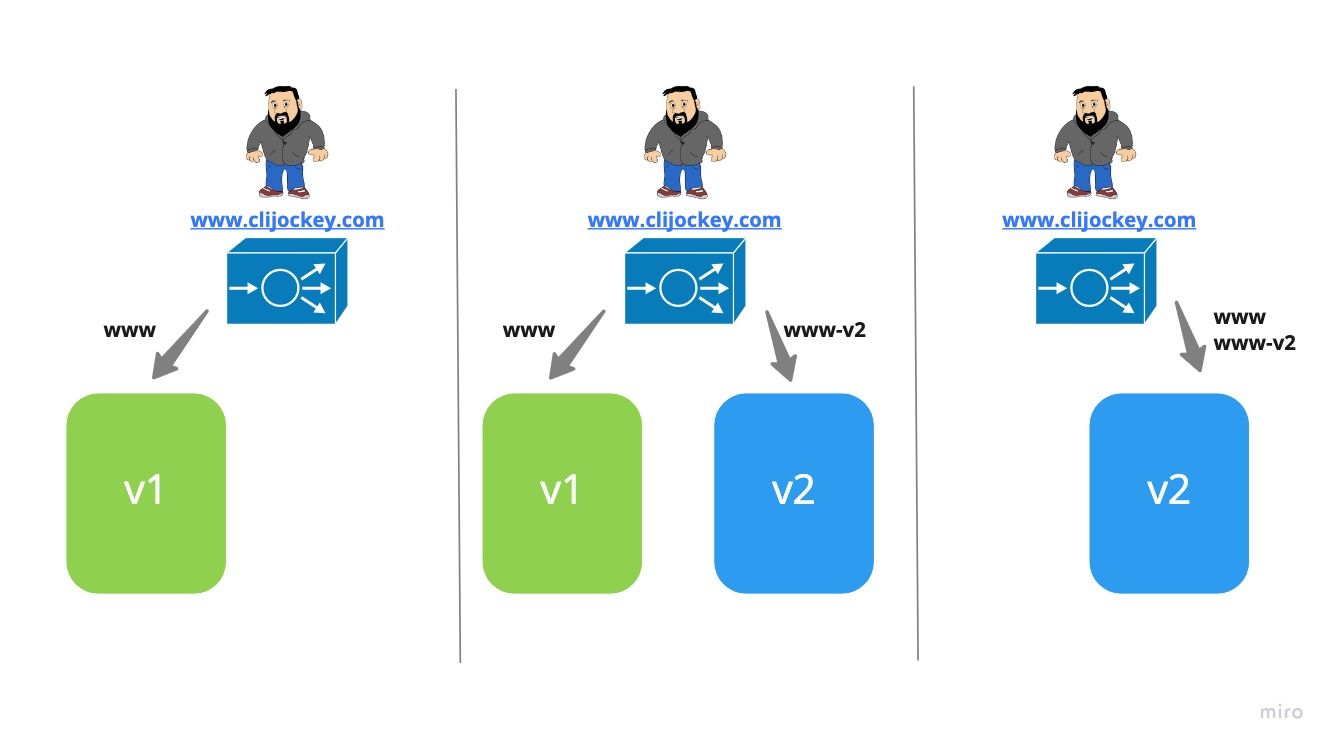
Kubernetes
# Deploy the first application
$ kubectl apply -f app-v1.yaml
# Test if the deployment was successful
# Then deploy version 2 of the application
$ kubectl apply -f app-v2.yaml
# Wait for all the version 2 pods to be running
$ kubectl rollout status deploy my-app-v2 -w
deployment "my-app-v2" successfully rolled out
# Side by side, 3 pods are running with version 2 but the service still sends traffic to the first deployment.
# Once your are ready, you can switch the traffic to the new version by patching the service to send traffic to all pods with label version=v2.0.0
$ kubectl patch service my-app -p '{"spec":{"selector":{"version":"v2.0.0"}}}'
# Test if the second deployment was successful
# In case you need to rollback to the previous version
$ kubectl patch service my-app -p '{"spec":{"selector":{"version":"v1.0.0"}}}'
# If everything is working as expected, you can then delete the v1.0.0
# deployment
$ kubectl delete deploy my-app-v1
Cloud Foundry
A number of plugins exits to the cf cli, using pipelines to make this easier or you can make manual changes.
# The first thing to do is have an app running;
$ cf push blue -n www
# Update the application with required changes and push under a different name;
cf push Green -n www-v2
# Will now have two different version of the app running with different URL's (www.clijockey.com & www-v2.clijockey.com just like the Blue/Green image above)
# Now move the original route/URL to the new app versions
$ cf map-route Green example.com -n www
Binding www.clijockey.com to Green... OK
#The route will now be pointing to both versions.
# Now unmap the route to the old instance
$ cf unmap-route Blue example.com -n demo-time
Unbinding www.clijockey.com from blue... OK
Rolling Deployment
To slowly introduce the new versions of your application you can use this strategy. A rolling update is done by gradually brining app instances up, as they prove to be working and health the older versions are removed, this carries on until only instances of the new version are running.
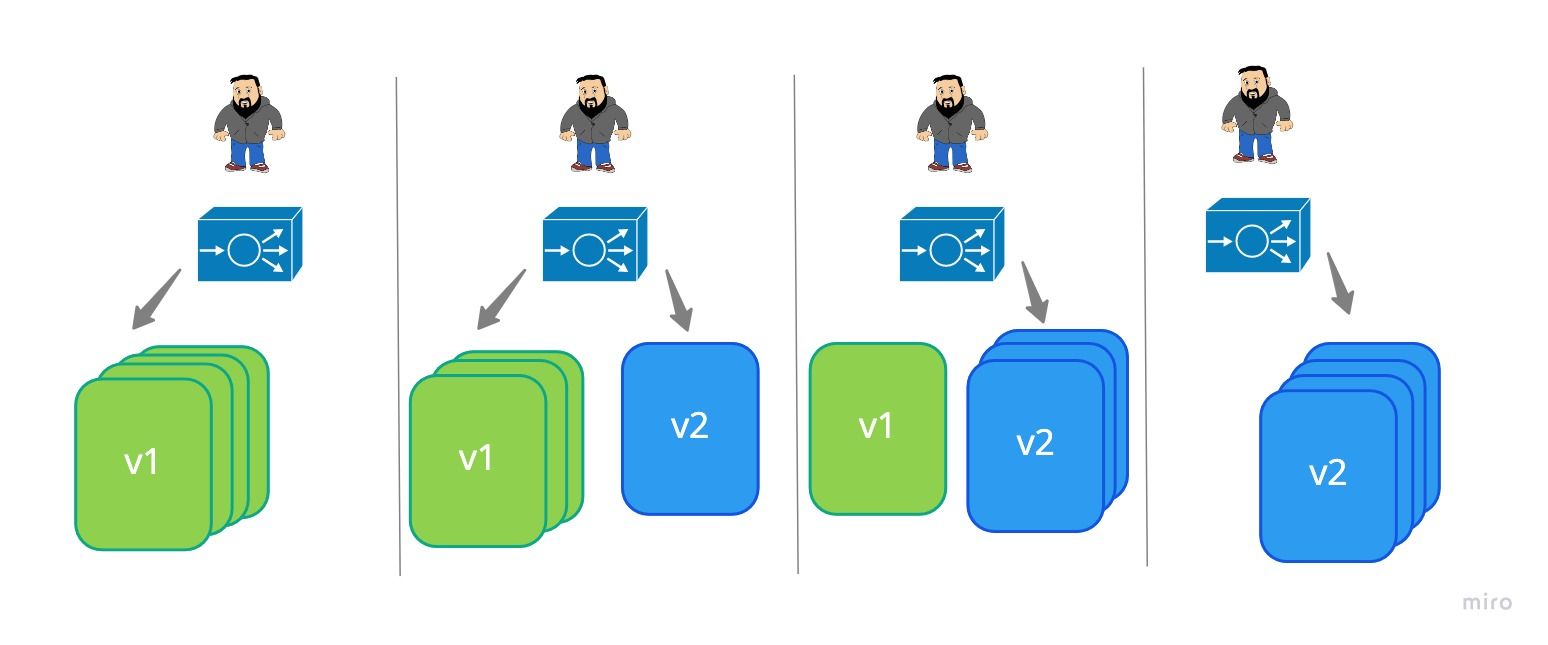
Kubernetes
The K8s rolling deployment (aka rolling update) deployments use readiness checks to determine if a new pod is ready and before scaling down the old pods.
The following is an example of how configure rolling updates in your deployment manifest
spec:
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 1
Cloud Foundry
The v3 API of Cloud Foundry has a native way of achieving this strategy with cf push (aka zero downtime push). When you want to perform an update to an existing app use the following command;
cf v3-zdt-push <app>
Over time this will become the default behaviour I’m sure.
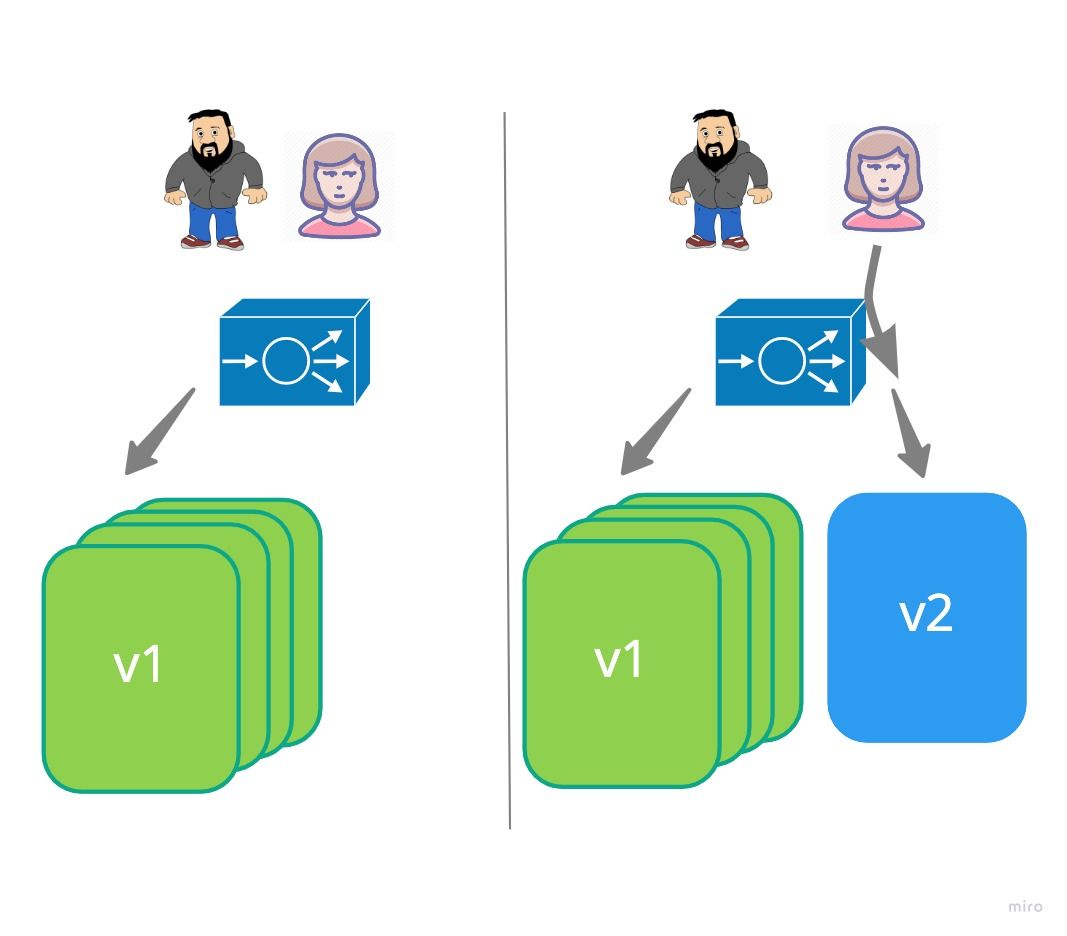
A/B Testing
In some circumstances you may want to route a subset of users to new functionality. This is what is called A/B testing. Usually more around making business decisions rather than a deployment strategy however its a valid method nether the less.
It can be used to test the impact of a certain feature, or based on metrics understand how certain changes are received/used. It enables multiple versions to be run in parallel giving control over traffic flows. You need to consider much more, like distributed tracing, metric collections, troubleshooting etc.
Typically the types of things you may distribute traffic is;
- Small percentage of users
- GeoLocation
- Browser/operating systems
- Cookies
- Languages
- Screen sizes
- Header values
Kubernetes & Cloud Foundry
No native constructs for this pattern, usually require additional components to be deployed - something like a service mesh!
Deployment Issues
When things go wrong what do you do? In the past, when it comes to Cloud Foundry, the discussion would go in one of two directions;
- Fix Forward
- Push older version
Following some of the deployment strategies discussed should reduce the chance of needing to fix a problem however having a plan is should still be high on the list.
If you are making small and frequent releases fixing forward is always easier because less has changed. In the past during my six monthly 72 hour change windows for certain services the only option often was to fix forward due to the value of changes and also due to schema changes but it was painful. What I mean by fix forward is rather than going back to the old working version you would find the issue and resolve it in production. If fixing forward you would just push the new, “patched” version.
The other option would be to go to your source control/artefact registry and push the last know working version. This may take a little bit of time (although quicker than fixing forward) however the risk exists that its not the exact same bits (due to the build process) for the droplet (aka container image for comparison outside of Cloud Foundry).
We now have an experimental feature in the v3 API that allows for rollback within Cloud Foundry/PAS. You can now get a list of previous droplet versions for the app with cf v3-droplets and cf v3-set-droplet you can then use to switch the running instances to the previous droplet. In the K8s world you can use kubectl rollout.
Wrap Up
Each strategy has its own pros and cons which you need to weight up and carefully consider what is best for your application. The key thing, as mentioned at the start, is developer productivity and making it easy for developers/operators to implement these strategies in a consistent manor. This also helps enable the continuous deployment of features and value without fear.
Newer technology is emerging to make the use fo these deployment patterns much easier, these in some cases are being embedded into the Pivotal Platform, Pivotal Ingress Routing etc. The technology is based around service meshes (Istio/Envoy).
Which ever strategy you prefer it should be incorporated within a deployment pipeline (many examples of this using Concourse and Spinnaker, let alone Jenkins/GoCD etc.)