
Before I start with “why” Bosh, what is Bosh?
It is…
- an open source tool for release engineering, deployment, life-cycle management and monitoring of distributed systems
- installs and updates software packages on large numbers of VMs over many Iaas providers, with the absolute minimum of configuration changes
- orchestrates initial deployments and ongoing updates that are
- Predictable, repeatable and reliable
- Self healing
- Infrastructure-agnostic
Additional information can be found at bosh.io or its Wikipedia page.
Typically, operations team(s) need to take care of;
- Cloud Orchestration
- Operating system
- Package Mgmt.
- Scaling
- Self-healing
- Storage
- Networking
However, bosh deploy takes care of all this.
So back to the original question, “Why Bosh”?
When thinking about the above characteristics, a number of tools spring to mind. At the start, I would try and compare them to Bosh. The tools that I would use as a comparison would be;
- Puppet/Chef/Ansible
- Terraform
- Propriety vendor tools
While on face value these tools serve similar purposes, they do things in very different ways (I would not say I was an expert in these tools). The tools above look at the deployment/installation very much from the server perspective (or infrastructure perspective) while bosh views it from a service perspective, with the infrastructure merely being an implementation detail.
I am not dissing these tools, they all solve a problem (and in some cases different problems).
The journey to the creation of Bosh is not straight forward and had given people a number of scars, originally Cloud Foundry used Chef as its deployment mechanism. A video I like that touches on some of this is from a CF Summit session;
It is possible to go on and on about the benefits and details of Bosh so I have decided to call out my top 3 reasons!
- Day 2 Operations
- Multi-Cloud
- It works!
Day 2 Operations
Yes Bosh creates all the VM’s (including installing the software) but that’s not particularly difficult, the market is full of tools for this (I may even have a terrible script knocking around to do this).
My top reason is the day 2 operation capabilities (which is an extensive list in its own right). Over the years I have discovered, the hard way, that getting something up and running is the easy bit, the difficulty is feeding and watering it (day 2);
- Patching
- Upgrades
- Monitoring
- Fixing/Repairing
- Logs
- Scaling
We can class upgrades and patching into the same category. How quickly are you able to roll out a critical patch for a bug that has been identified? This, from experience, can be months or years and I have worked in banks and Government environments. Don’t take my word for it though, just search Google for recent security breaches and the attack vectors used. What Bosh does with patching and upgrades is blow away the current infrastructure with new versions of operating systems, system patches etc. using canary techniques to allow for zero downtime.
I have seen an increasing number of PCF customers take this to the next level and repave (reinstall everything) once a week which means any APT’s have a max 7 day window to do anything.
Bosh also knows what process should be running on servers, including how to restart them. As a result, should a problem be discovered, the process will be restarted. Worst case, the whole instance recreated. Should Bosh discover that an instance has disappeared (because of an IaaS issue) it will just recreate and integrate it back into the system. This means that monitoring is not as critical as before, it used to be very reactive and human driven, the system can self-heal.
Now because Bosh knows how the system works and also how to deploy components (including taking care of integrations, certs etc.) in a reproducible, consistent and predictable way we have a situation that can easily scale up or down.
All this means that as an operator we no longer need to spend 80% of our time being reactive to mundane tasks but focus on improving services and offerings. I am yet to meet anyone who enjoys applying patch upon patch every week, to then be called out to restart some system process that has crashed and is easily fixed. A large amount of this pain can be alleviated with Bosh
I am constantly amazed by what some customers are able to achieve when it comes to the size of their operations team(s). Partly because of tools like Bosh, they are able to maintain crazy large environments with teams of 4 - 8! A public reference is Comcast who have a team of 4 for 1000’s of applications and developers.
All this is why I have Day 2 at the top of my list.
Multi-Cloud
The last 3+ years I have heard the need for people to have the ability to deploy things on-prem, in different clouds etc. What you get with Bosh is the ability to deploy to an ever growing list of IaaS’s, it will abstract the underlying infrastructure from the operator and allow them to focus on getting all the things up and running.
At the time of writing, Bosh has capabilities with the following IaaS;
- VMWare
- GCP
- AWS
- Azure
- Opensack
- Alibaba
- Softlayer
- Virtualbox
- Kubernetes
- Docker
- CloudStack
- Oracle
I am pretty sure this covers over 99% of the Clouds used.
It Works!
In the last year I have used both Open Source Bosh and the Bosh that is bundled with PCF and generally, it works very well. The more I use it, the more I love it as a tool.
This comes from many years of operational experience and doing lots of the things we take for granted with Bosh manually, on a very regular basis with pain.
What can it deploy and manage
It started with Cloud Foundry, however, it can pretty much be used for any distributed service offering. Well, that could be expanded to say pretty much anything. Examples of things that I have personally used with Bosh are;
- Cloud Foundry
- Concouse CI
- MySQL
- Redis
- RabbitMQ
- Kubernetes
It also supports both Linux and Windows. A number of community releases are here.
So what’s the catch?
“This sounds too good to be true?” I am sure this is something I said a year ago and customers/prospects I meet say the same.
This is not written by someone who has drunk some “Kool-Aid”! If you know me you will know that I am cynically northern (North of the UK).
The two things that jump to mind on this subject are;
- Steep learning curve
- Large/Complex manifest
The learning curve for Bosh IS very steep, the best picture I have seen of this comes from the CF Summit talk “7 Stages of Bosh” from back in 2015. We all start thinking it’s not too bad and then BANG!
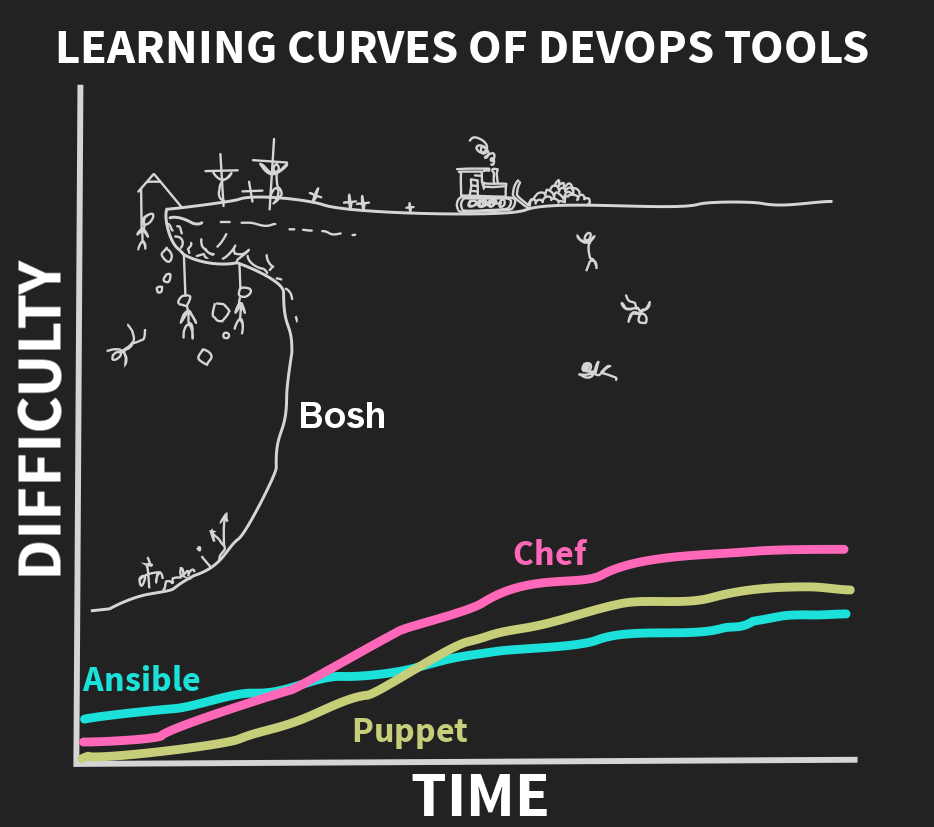
However this only really applies to you if creating Bosh releases, as a consumer of Bosh releases you are safe.
By the time you have been using Bosh for a while you will feel like a Yaml Architect. It is Yaml heavy, in fact, the last count of lines in a PCF deployment is around 7,500. When you get to large, complex systems, these files can be difficult to manage and maintain. But that’s where companies like Pivotal come in.
I also discovered that the most seasoned Bosh users and release creators can get a little bit lost some times in the Yaml for deployments that they are not familiar with. This is getting better and better all the time as new features are rolled out and also documentation is improving.